
CQRS, Symfony, ElasticSearch and React
Software architecture is an extremely interesting and useful topic. A lack of architecture and your code will turn into some spaghetti mess. But if you overuse it, your code will be over complicated and equally hard to work with. A few years ago I dived into the academic literature, and various online sources. This post is the first of a series about what I learnt and what I found useful in my past professional experience.
Command Query Responsibility Segregation, or CQRS, is a very popular technical subject.
A Github search of “Symfony CQRS” returned 117 repositories, including some examples on Symfony 4,
a few bundles, a boilerplate and a skeleton (for Symfony 2/3).
But beyond all the hype, CQRS is at core a very simple concept.
We will explore it in this article, and see how it impacted modern application architecture.
What is CQRS?
CQRS pattern dictates to separate read from write.
Each will have different models, respectively queries (think of a “SQL query”, it specifies a read) and commands (from the Command pattern). The basic principle is nothing more, nothing less.
A schema is worth a thousand words, let’s compare and see the difference between a standard architecture and one following CQRS:
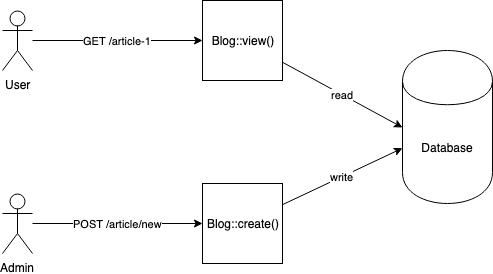 A Blog web app. One user reads an article, while an admin is writing a new one.
A Blog web app. One user reads an article, while an admin is writing a new one.
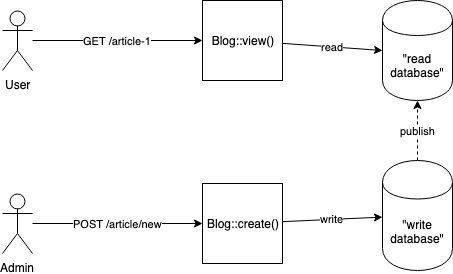 The same app, implementing CQRS, with 2 different data storages for read and write (optional)
The same app, implementing CQRS, with 2 different data storages for read and write (optional)
Regarding implementation, read and write models could share the same SQL database, and just have different tables.
Typically, one of the many reasons to use CQRS is performances.
Then the read table would contain denormalized data, nested structures instead of JOIN, etc.
It could also be updated asynchronously, so writes do not impact read performances, ie. with a bus / message queue.
If you want to read more on the subject, there is a great article on Martin Fowler “bliki” and this post by Udi Dahan which go into further detail.
Just an extra note before moving on: CQRS is not related per se to Domain-Driven Design.
I see those 2 as orthogonal architecture patterns, one can be implemented without the other.
The source of the confusion is likely that they were both described in the “big blue book”,
by Eric Evans. But I believe it is a mistake to always introduce both together,
they are better explained separately and they have different use cases.
You may already be using it: Symfony and ElasticSearch
We detailed how CQRS could be implemented, with a fast and denormalized read data storage,
a relational (SQL) write data storage, and some asynchronous update mechanism.
But isn’t exactly what FOSElasticaBundle do?
ElasticSearch can be used as an extremely fast document data storage, with nested structures.
The bundle provides Doctrine listeners, and you can even push those to a queue.
I’m not saying this is an optimal implementation. Neither what I described is the only possible implementation.
But I find funny that a lot of developers deal with something close to CQRS, without even realizing it. Without fancy names or buzzwords. Just because CQRS is a way to solve real problems, and it is not as complex as you may be led to believe.
Personal story, on my first contract as a senior consultant, I met a team who implemented CQRS, without knowing it.
They had a Symfony application with a SQL database full of complex, entangled, data. They had some asynchronous mechanism writing a “flat” version to ElasticSearch. And they had a lot of users - sometimes, even peaks caused by TV ads - consuming that data. They had everything, but the name.
Still, knowing the name of what you are doing helps. It helps when looking for resources, both documentation and libraries. More importantly, the name helps you communicate what you are doing, in the way of an Alexandrian language.
CQRS v2.0: Flux in the Javascript ecosystem
In 2014, Facebook introduced the Flux architecture. One of its most popular implementation is Redux, typically used with React, but we also have Vuex for Vue.js, etc.
Let’s have a look at the architecture, and compare it with CQRS:
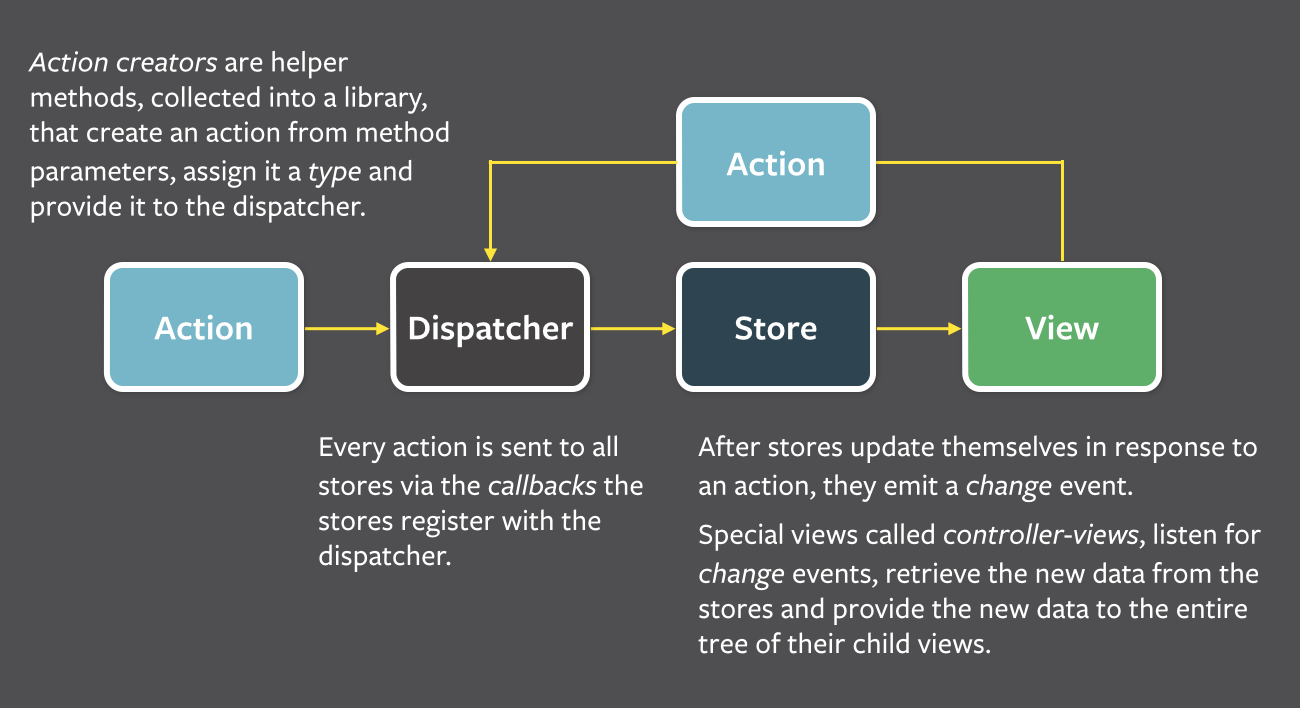 Diagram from Flux documentation
Diagram from Flux documentation
We find (again) a unidirectional data flow. Actions would be equivalent to commands, they encapsulate all information needed to perform an action, and they represent a “write”. The change event is the read model, the query. Both commands and queries share the same data store, but that’s an implementation detail.
In the end, the biggest difference comes from the reactive nature of Javascript apps. Data flows, and not only on User actions. But that’s more of an update than really a new architecture.
The pattern from 2003 (Eric Evans) is still relevant today, that pattern being adapted from the CQS principle (Bertrand Meyer, ~1989). I hope I convinced you that studying software architecture is more useful that it sounds, and not to stop at looking at implementations. “Old” ideas are still useful while developing PHP or Javascript in 2019, and they are not as complex as they seem.
Comments